Getting reconciliation right in the “decade of data”
Digitisation of manual systems has been pushed to the top of banking executives’ agenda since an early push in the early 2000s to automate parts at the very back-end of the system. However, innovation in this area has stalled and operations reliant on people power and spreadsheets are still prevalent.
One process that often gets delayed is automation of reconciliation functions from onboarding, compliance, trade data and regulatory reporting. Reconciliation is an essential control function in financial services, aimed at eliminating operational risk that can lead to fraud, fines or in the worst case, the failure of a whole firm.
FinTech Futures sat with Douglas Greenwell, reconciliation expert at Duco, to explore how firms can automate and streamline their reconciliation functions today, the options available for updating and consolidating systems, and the potential for machine learning to revolutionise how these processes are carried out.
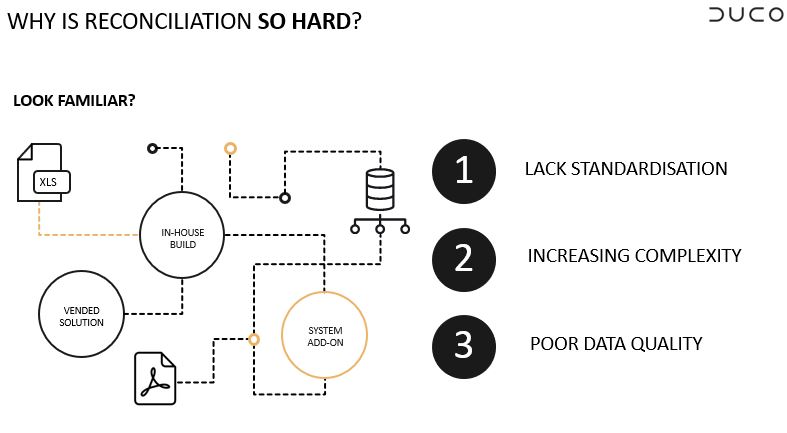
“What I think most organisations face is represented in the diagram (figure 1) where there are a multitude of systems, different processes, technology types and computing. Within that, there are three key reasons that are making this difficult: a lack of standardisation, increasingly complex instruments being traded, and poor data quality,” said Greenwell.
This is why Duco penned a paper that looks at the whole maturity of reconciliation – a best practice guide for all reconciliation practitioners, or executives overseeing a reconciliation function. “We believe there are five key stages organisations can find themselves at,” said Greenwell. “Firms can use the Reconciliation Maturity Model to benchmark where they are in terms of reconciliation best practice, and what steps are needed to improve automation, efficiency and operational resilience.”
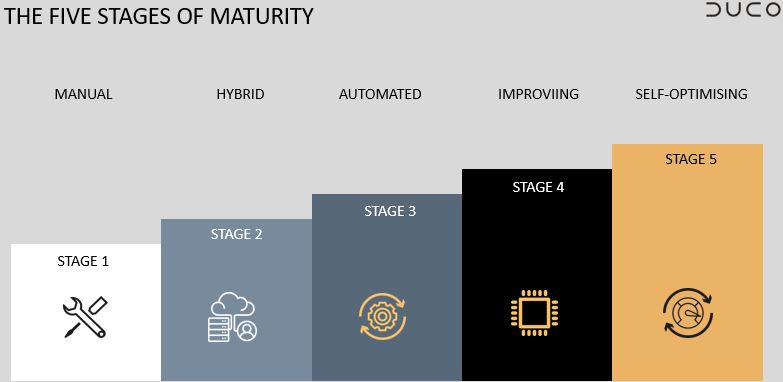
“We find that most organisations are at the hybrid stage,” he added. This is stage two, where a firm’s complexity is such that spreadsheets and manual processes alone are not enough to deal with the issues it faces. “This is where firms will have multipoint systems in place, resulting in a patchwork of disparate processes and spreadsheets. The goal is to move from this hybrid stage to the automated stage and beyond.”
Most institutions struggle to move from stage two to stage three. To do so requires a fundamental rethink of the reconciliation architecture, from point solutions that specialise only in certain type of data, to agile technology that can onboard and automate new reconciliations very quickly, even with new types of data the firm has yet to deal with.
Once widespread automation has been achieved, the aspiration – and where organisations really start to drive tangible value – is to move beyond stage three and four towards a place where errors are spotted and corrected automatically, and the need for inter-system reconciliation is all but eliminated. This can be achieved through machine learning.
“Machine learning, when implemented properly, will enable firms to spot and correct data errors, inconsistencies and poor quality at source, before issues are created in downstream systems,” continued Greenwell. “Reconciliations are often used as an ‘after-the-fact’ control point. But if you can fix the data at source – by using machine learning technology that has trained on past data – these reconciliations will start to flag up fewer and fewer issues, and can be eventually be removed entirely.”
However, not all machine learning technology is created equal, and there are some pitfalls that organisations should be wary of. For example, a machine can only learn from the data it trains on. If the machine learning technology is installed on an on-premise system, for example, and only able to train on data within the boundaries of one organisation, the scope for improvement is limited. But if the machine learning technology is cloud based, training on industry-wide data, there’s a flywheel effect – the more data that becomes available, the more accurate the models and predictions become.
In terms of customer data, when that data is corrupted from the start, this represents a real issue. But how can firms prevent having to reconcile the data in the first place? Brittany Garland, director of operational risk & regulatory compliance at IHS Markit, told FinTech Futures that firms should ensure the data is clean from the start and aggregated at the point of account opening – ensuring that the data continues to be maintained throughout the lifecycle of the account.

FinTech Futures sat with Douglas Greenwell, reconciliation expert at Duco
“We can start to get that data from the point of entry by introducing tech elements in the onboarding process. The onboarding process is extremely manual and heavily reliant on email communications, which are prone to human errors, and falls short of collecting all the data on a client at the point of account opening,” said Garland. “To start solving these challenges, it’s important to digitise these processes and have full transparency of your data requirements at the point of onboarding, removing manual intervention.”
Chad Giussani, head of transaction reporting compliance at Standard Chartered Bank, explained that there are additional hurdles with regulatory reporting data and the requirement to obtain additional data on a client post-account opening. But his solution came with more regulatory intervention. “What’s been helping us is the increased adoption of data standards,” he said. Giussani references the ISO standards and legal entity identifiers (LEIs). “Once you use standards under specific regulations, like the Second Markets in Financial Instruments Directive (MiFID II), so it has to be ‘x long’ and it ‘can or can’t contain numbers’, this helps with usable checking and referencing external sources to ensure validity.”
Although regulations help, they can also hinder certain departments throughout the trade and data lifecycle. Greenwell believes that the overriding issue is that most of the technological infrastructure that organisations are grappling with is centred in the IT departments as opposed to the reconciliation operation itself. “Systems need to be more self-service in order to fulfil the need that comes out of the front office or new regulatory obligations. The reliance on legacy technology has led to a massive explosion in both manual and automated hybrid processes,” said Greenwell.
Having data formed accurately at the start of the process improves its chances to stay clean throughout the entire trade and data lifecycle, especially within areas that are often overlooked such as the archiving and deletion processes. Most firms focus on the trade and regulatory reporting elements due to audits that can lead to massive fines if the data is inaccurate or misleading. There are also a variety of reasons for data to change over time such as: new regulatory requirements, mergers, acquisitions, name changes etc.
But keeping data clean throughout this process can help allay any fears of such legal enforcement action. This is where the reconciliation maturity model comes in, as it can assist organisations in reaching that clean state. This can help firms to develop a robust model and follow best practices for new data and regulatory requirements.
“The key lies in organisations addressing technology stacks. Firms should use technology that is fully resilient and empowers employees in multiple geographies,” added Greenwell. He believes that the model can provide that sense of empowerment in both operations teams and IT departments, while also assisting with cost-cutting.
Click here to download the full Reconciliation Maturity Model
Sponsored insights from Duco










































