Estimating Libor damage past – automating index surveillance future
In the wake of scandals involving manipulation of market indices, can statistical learning theory be used to detect and fix anomalies in Libor and other market indices? Therese Kieve & Professor Michael Mainelli of Z/Yen run the maths …
In 2012 US and UK regulators fined Barclays nearly £300 million for manipulating the London Interbank Offered Rate from 2005. The scandal led to the resignation of Barclays’ chief executive, Bob Diamond, and its chairman, Marcus Agius. The Libor manipulation scandal widened to fines for UBS, JP Morgan, and Citigroup, and the scandal is not over with more commercial litigation and criminal investigations underway.
Despite the fact that this may have been the first time the general public heard of the London Interbank Offered Rate, the 10 Libor currency rates are among the most widely used interest rate benchmarks in finance. The British Bankers’ Association created Libor in 1986 to help variable rates on interest rate products, derivatives, corporate loans, and consumer lending. Analysts estimate up to $300 trillion worth of financial contracts are tied to Libor.
Until 2013, the BBA surveyed a panel of banks for different currencies and maturities, asking, “At what rate could you borrow funds, were you to do so by asking for and then accepting inter-bank offers in a reasonable market size just prior to 11am in London?” From these submissions, an average is calculated once data points at the top and bottom of the range have been excluded. There are fifteen borrowing periods or maturities. In the case of one of the most widely used of the ten rates, USD Libor, up to 18 banks were surveyed. The “USD 3-month Libor” is the rate at which banks estimate they could borrow in US dollars for three months. The scandal was possible because banks provided their own ‘estimates’ of their borrowing rates to the BBA, without necessarily referencing actual transactions, and the BBA appears to have done little to validate the rates submitted. Mervyn King, Governor of the Bank of England, quipped that Libor was “the rate at which banks were not lending to each other”.
The scandal has already led to an imposed change of Libor ownership from the BBA to a subsidiary of ICE, and a new regime of EU and UK regulation for indices and benchmarks. Oddly, under the new regime transparency has lessened. Bank submissions data must now be purchased rather than being freely available as before with the BBA. Still further investigations have been launched into the possible manipulation of foreign exchange and other markets. Investment managers, asset managers, pension funds, sovereign wealth funds, and other large investors, need to look back and analyse the damage caused by Libor manipulation for the sake of their beneficiaries. Regulators need to look forward and establish ways of preventing similar scandals in other benchmarks and indices.
Libor Anomalies Study
In order to restore the credibility of these important reference rates, financial regulators have been studying possible options to avoid manipulation in future. A key component is early detection through better surveillance. Libor manipulation was detected mainly through the interception of messages sent between traders at rival banks that contained information on their trading strategies and future pricing. Automated surveillance of submissions data that could identify anomalies quickly and reliably would be greatly appreciated.
Equities surveillance research has lessons for Libor and other benchmarks. In 2004 and 2005, Z/Yen conducted a successful, study of automated equities trading surveillance. This study brought together five leading banks, the London Stock Exchange, Sun Microsystems, and Z/Yen’s analysts [Mainelli and Yeandle, 2006, 2007]. The study showed that best execution could be estimated, trade by trade, for compliance purposes. We published the results in two journal papers and built a best execution compliance workstation.
Similarly, in late 2012, we created a team for a Libor anomalies research study investigating the feasibility of using statistical learning theory techniques to automate the detection of anomalies in financial indices and benchmarks using Libor as a test case.
SVM Approach & Data
Our Libor anomalies study used classification and prediction tools based on statistical learning theory to undertake predictive analysis of the data. Z/Yen’s proprietary methodology for statistical learning theory is PropheZy. Support Vector Machines (SVMs) are statistical learning theory algorithms that develop classification and regression rules from data, largely non-parametrically. As a think-tank with an emphasis on measurement, Z/Yen uses SVMs widely, in financial services in areas such as straight-through processing and risk-based pricing, as well as in other sectors ranging from charities to television, retail, and property.
The basic idea was to use historical submissions and current submissions to cross-validate every individual bank’s submission each day. The data for this study consisted of $3-month Libor submissions from 15 banks over the period 4 January 2005 to 30 December 2011, obtained from Thomson Reuters in March 2013. The dataset contained approximately 30,000 data points. Our focus was on $3-month Libor as we believed it was one of the most widely used Libor rates.
Initial testing was performed on a small extract to determine the predictive nature of Libor data. Once the data was found to be predictive, the focus then moved to predictions at a granular level. SVM training data was extracted from daily Libor submissions over the period 2005 to 2011. This training data was used to predict Libor submissions one day ahead. For example, the 2005 dataset was used to predict submissions for 3 January 2006. The 2005 dataset was then updated with the actual submissions for 3 January 2006 and then used to predict for 4 January 2006. This iterative process was continued until a full set of predictions were obtained for each business day over the period 3 January 2006 to 30 December 2011 (a total of 1,516 days). The predictions were then evaluated for accuracy and examined for potential anomalies.
Results & Analysis
 It is common practice to measure an SVM’s performance by calculating its Mean Square Error (MSE). The accuracy of the SVM predictions over the entire period is high as can be seen by the low MSE values and the high R-squared values in the table below.
It is common practice to measure an SVM’s performance by calculating its Mean Square Error (MSE). The accuracy of the SVM predictions over the entire period is high as can be seen by the low MSE values and the high R-squared values in the table below.
Given the nature of the Libor process, we would expect high values of R-squared, thus the small differences may have importance. As the table is sorted by R-squared, it shows, for 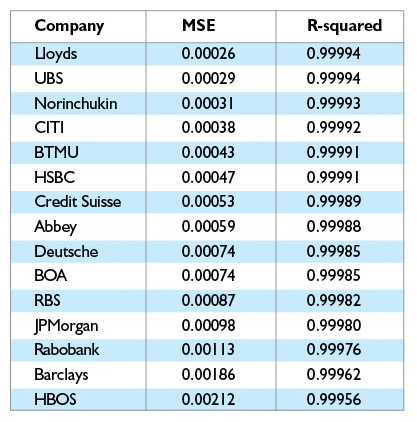 example, that Lloyds TSB’s submissions were more predictable than HBOS. This may indicate that banks at the bottom of the table require a closer look. This R-squared is for the entire six year period. R-squared values in shorter periods are the subject of more interest. With more research budget, it would be worthwhile to analyse in detail the differences in two separate data periods, pre-2008 and post-2008 onwards, as the volatile market conditions in 2008 add a layer of complexity.
example, that Lloyds TSB’s submissions were more predictable than HBOS. This may indicate that banks at the bottom of the table require a closer look. This R-squared is for the entire six year period. R-squared values in shorter periods are the subject of more interest. With more research budget, it would be worthwhile to analyse in detail the differences in two separate data periods, pre-2008 and post-2008 onwards, as the volatile market conditions in 2008 add a layer of complexity.
Outliers
It is useful to look at the variation in the R-squared values over the period as a proxy for detecting unusual movement. If we examine the period leading up the financial crisis (right), we can see that the R-squared for all the banks over 2006 were consistently high. This changed over 2007 and even more dramatically in 2008. In 2008, the R-squared values for Barclays, HBOS, JPMorgan, and Rabobank look particularly low and suggest further investigation.
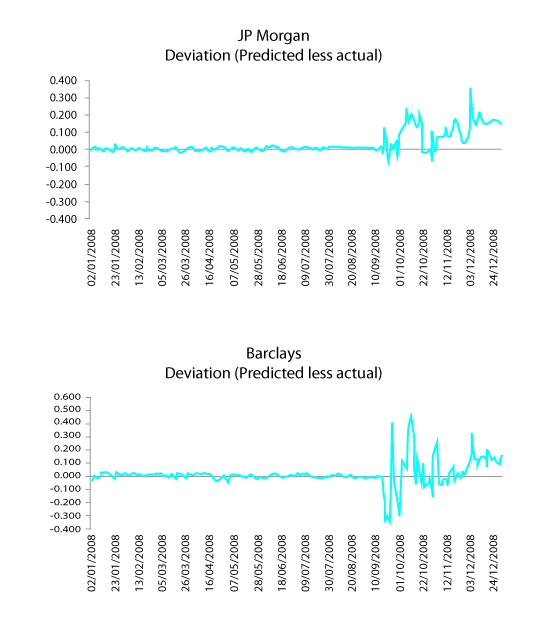
JP Morgan & Barclays
If we examine the deviation of the predicted from the actual rates submitted for Barclays, JPMorgan, HBOS, and Rabobank in 2008, we notice that there is little deviation until September 2008 (the onset of the financial crisis). For the remainder of 2008, Barclays shows large positive deviations, JPMorgan shows smaller positive deviations, and HBOS shows a large negative deviation followed by small positive deviations. Rabobank shows fluctuation between negative and positive deviations. The positive deviations, particularly in the case of Barclays, could indicate times when Libor was understated. Under normal circumstances, one would expect that at periods of higher volatility there would be both positive and negative deviations. The positive deviation for Barclays at the end of October 2008 coincides with the time Paul Tucker and Bob Diamond had a conversation about the level of Barclays’ Libor rates.
The December deviations for both Barclays and JPMorgan appear strikingly similar (contrast with the negative deviations of HBOS and Rabobank below) which would suggest that a further look into specific actions
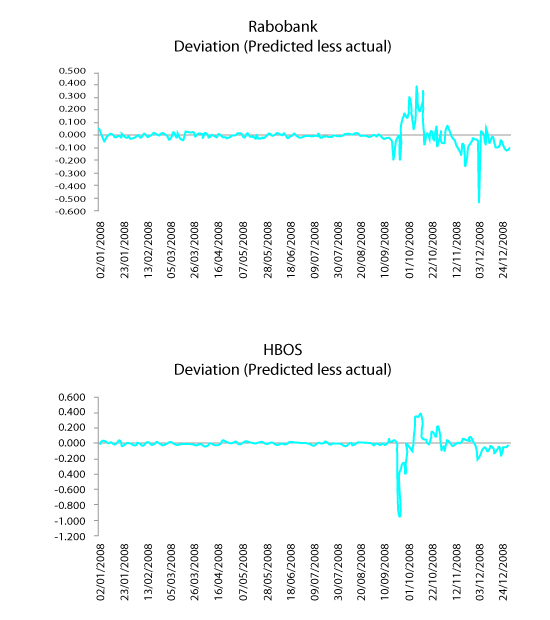
HBOS & Rabobank
within both banks at that time might have been appropriate.
In contrast, the graphs for Lloyds TSB and Norinchukin bank show a much smaller deviation even over the most volatile period. It is unlikely that these banks would need a closer look. This preliminary approach could be an effective tool in identifying banks that are possibly engaging in manipulation of financial indices.
Discussion
While there is no problem in principle with real-time prediction for surveillance, further research is needed to explore the use of anomaly detection in real-time and how it would integrate with ongoing compliance processes, e.g. the rate of false positives is important and could make this approach too costly to administer. This study was conducted retrospectively and without access to contextual information, e.g. phone calls and emails indicating collusion. Forensic research on past Libor records and related data, e.g. email traffic, would help understand correlation between the banks’ submissions and confirm instances of possible collusion with anomalies in the surveillance approach.
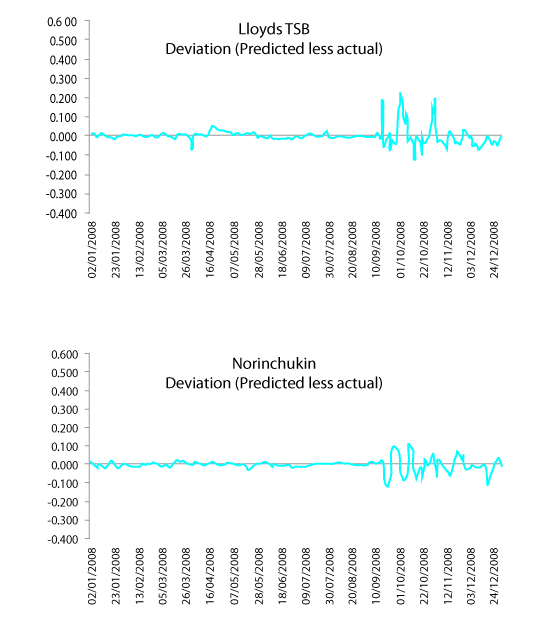
Lloyds TSB & Norinchukin
Systematic low-balling of Libor, perhaps in order to gain a consistently better credit rating, would be difficult to detect without comparisons of reported Libor with actual borrowing costs.
It would have been especially helpful to have the resources to add and explore more ‘environmental’ data, e.g. credit default swap rates on the banks studied or wider market indicators such as government bond rates or credit rating changes. The analysis so far is based purely on inter-bank submission comparisons. For a bank compliance officer or a regulator much wider environmental measures would be extremely useful in (a) providing context, and (b) helping to calibrate and improve anomaly detection.
Other Libor indices could also be studied, the remaining USD periods and the other nine currencies over their fifteen borrowing periods. We wonder about the likely results for Libor indices in currencies that were not exposed to the same level of scrutiny as USD 3-month Libor. More widely, this Libor anomalies approach might apply in other markets, e.g. foreign exchange or metals or shipping.
This technique, with some simplifying assumptions, could be used to estimate what the historic Libor should be. In theory, one could estimate what the likely submission should have been for a guilty bank and then recalculate Libor. Fraudulent submissions can have significant effects, especially when they force other submissions out of the averaging process by pushing them among the too high or too low submissions which are discarded. Thus, fake rates supplant real rates in the averaging.
Conclusion
This research shows that a statistical learning theory approach appears to identify anomalies in financial indices and benchmarks at the time of creation. Further research could lead to the incorporation of these algorithms into ongoing, daily surveillance of markets and indices, an approach Z/Yen terms Environmental Consistency Confidence [Mainelli, 2009]. We believe that this approach could matter for:
- regulators – as a new method of market surveillance;
- investment managers, asset managers, pensions fund, other large investors, and their litigators – to estimate damages to clients;
- bank compliance officers – as a way of implementing semi-automated internal surveillance;
- auditors – using this approach forensically for detection of suspicious activity;
- academics and researchers – for wider validation, testing, and applications, as well as extending this research, e.g. incorporating fractal components and ‘big data’ visualisation.
REFERENCES
[1] Michael Mainelli and Mark Yeandle, “Best Execution Compliance: New Techniques for Managing Compliance Risk“, Journal of Risk Finance, Volume 7, Number 3, Emerald Group Publishing (June 2006).
[2] Michael Mainelli and Mark Yeandle, “Best Execution Compliance: Towards An Equities Compliance Workstation“, Journal of Risk Finance, Volume 7, Number 3, Emerald Group Publishing (June 2006).
[3] Michael Mainelli and Mark Yeandle, “The Best Execution: Trader or Client?”, Fund AIM, Volume 1, Number 1, Investor Intelligence Partnership (January 2007).
[4] Michael Mainelli, “Environmental Consistency Confidence: Scientific Method In Financial Risk Management“, Risk Management In Finance: Six Sigma And Other Next-Generation Techniques, Chapter 22, Anthony Tarantino & Deborah Cernauskas (eds), John Wiley & Sons (2009).
[5] Martin Wheatley, “The Wheatley Review of LIBOR”, HM Treasury (September 2012).
[6] Mark Yeandle, “Best Execution Compliance Automation“, Financial Services Research, Financial Services Research Limited (2006).
The authors would like to extend special thanks to Phil Cantor, Ian Harris, Bernard Manson, Vincent Mercer Bernard O’Dea, and Jan-Peter Onstwedder for their assistance in this study.







































